As blockchains tradicionais tendem a considerar os dados como um elemento secundário, separando o armazenamento da execução. Esta arquitetura dificulta o aproveitamento direto de grandes volumes de dados pelas aplicações on-chain e aumenta a dependência de serviços externos. A Irys supera este desafio ao integrar armazenamento, verificação e execução de dados numa única estrutura.
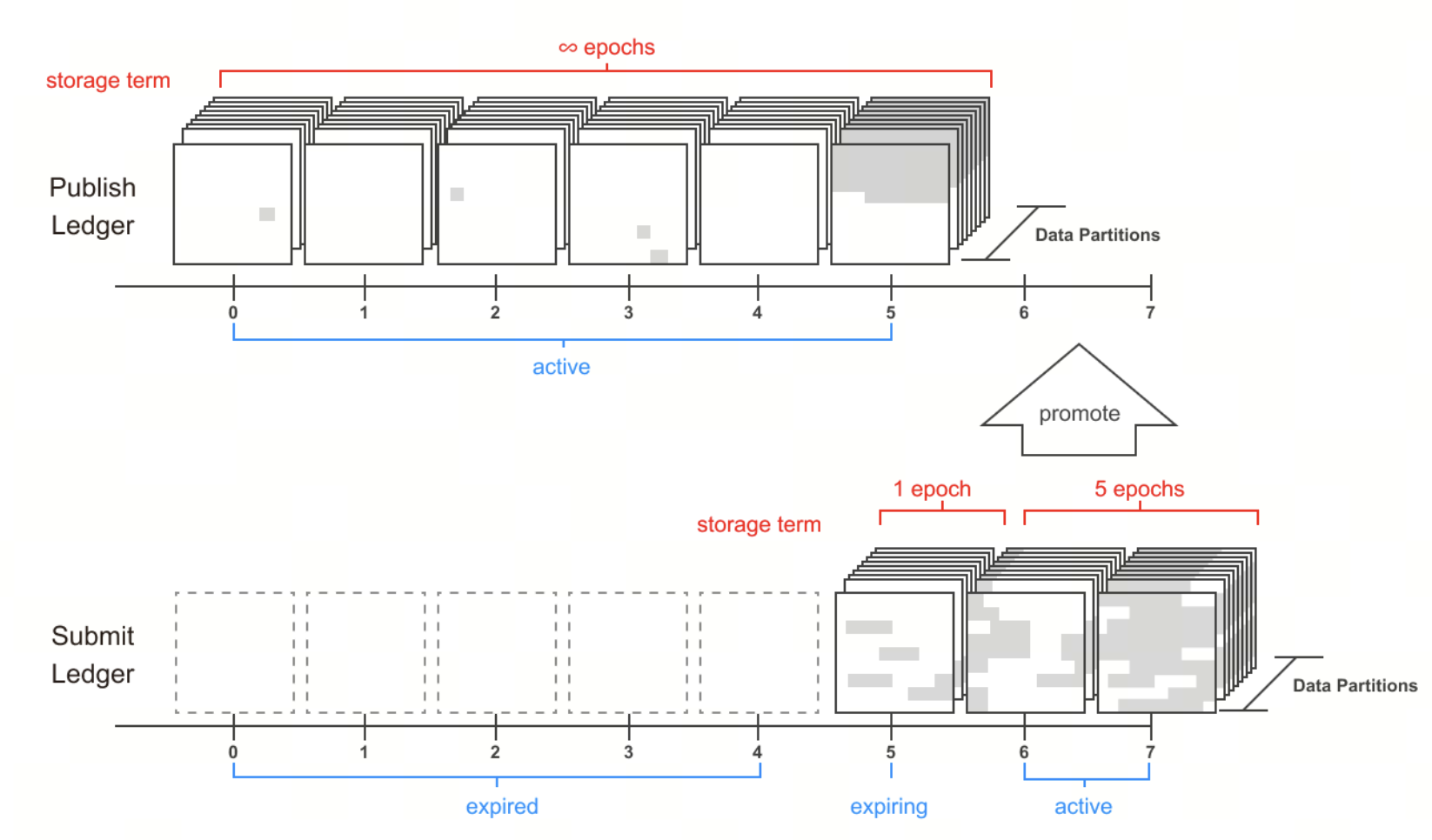
Para compreender a Irys, é essencial conhecer o ciclo de vida completo dos dados: desde o upload, passando pela verificação em toda a rede, até ao acesso e utilização. O mecanismo de armazenamento por partições e mineração (Partition Lifecycle) é fundamental para perceber a sua capacidade de verificação.
Princípios essenciais do armazenamento de dados Irys: camada de dados descentralizada e armazenamento verificável
A Irys assenta numa arquitetura Datachain, integrando os dados diretamente no mecanismo de consenso da blockchain. Ao contrário do armazenamento tradicional, os dados não são apenas preservados — passam a constituir um estado on-chain comprovável.
Neste modelo, cada registo de dados tem de ser confirmado pela rede como realmente existente e acessível. Este método transforma os dados de um elemento passivo num ativo comprovável, reforçando a confiança no sistema.
Além disso, a Irys funde dados e ambiente de execução, permitindo que os dados sejam lidos e processados em operações on-chain. Assim, a Irys deixa de ser apenas um protocolo de armazenamento, tornando-se uma camada fundamental de infraestrutura de dados.
Processo de upload de dados: do envio do utilizador ao registo on-chain
O upload de dados na Irys funciona de forma semelhante a uma transação de blockchain. O utilizador agrupa os dados e submete-os à rede, entrando assim no pipeline de processamento on-chain.
O armazenamento não é centralizado; os dados são divididos e distribuídos por várias partições na rede. Cada partição, com cerca de 16 TB de capacidade, constitui a unidade base da estrutura Irys, suportando a escalabilidade e o controlo de custos.
Quando os dados são escritos em blocos, o estado fica registado on-chain e avança para as etapas seguintes de verificação. Este percurso estabelece o caminho completo de escrita, servindo de base à verificação e recuperação posteriores.
Fonte: irys.xyz
Mecanismo de verificação de dados: como a Irys garante dados comprováveis (proof of storage / availability)
A inovação central da Irys consiste em integrar a verificação de dados no mecanismo de consenso. Cada bloco valida não só as transações, mas também a presença e acessibilidade dos dados.
Este processo baseia-se em amostragem e verificação de hash. A rede solicita continuamente aos nodos que leiam partes dos dados e executem cálculos, validando o armazenamento real em vez de uma mera simulação.
A Irys introduz um mecanismo de mineração de armazenamento: os nodos têm de ler e verificar blocos de dados de forma contínua para poderem participar na criação de blocos. Assim, a verificação de dados passa a ser central nas operações da rede.
Este desenho resolve o principal desafio do armazenamento descentralizado — confirmar a existência dos dados sem depender da confiança.
Recuperação e consulta de dados: acesso, indexação e invocação na Irys
Depois de armazenados e verificados, os dados podem ser consultados e recuperados através de identificadores próprios. Os nodos da rede devolvem o conteúdo relevante em resposta aos pedidos.
Ao contrário do armazenamento tradicional, a Irys permite a leitura e invocação direta dos dados por aplicações on-chain. Os Smart Contracts podem executar lógica baseada nestes dados, sem recorrer a API externas.
Esta estrutura legível e computável faz da Irys uma camada de infraestrutura robusta para aplicações Web3 orientadas por dados.
Garantia de disponibilidade: nodos, consenso e ciclo de vida das partições
A Irys assegura a disponibilidade dos dados a longo prazo com o mecanismo Partition Lifecycle.
A rede divide o armazenamento em múltiplas partições de 16 TB, mantidas através dos seguintes processos:
-
Partition Pledging: os nodos fazem staking de tokens para participar no armazenamento
-
Partition Packing: o Matrix Packing associa dados à identidade do nodo, evitando ataques de replicação
-
Partition Mining: os nodos leem dados e realizam cálculos continuamente para provar a existência dos dados
-
Ledger Assignment: nodos com melhor desempenho recebem dados reais e obtêm retornos superiores
Durante todo o ciclo de vida, os nodos têm de provar constantemente a sua capacidade de armazenamento, sob pena de perder recompensas e sofrer penalizações.
Se um nodo abandonar a rede, o sistema realoca automaticamente os dados, evitando perdas por indisponibilidade. Desta forma, a disponibilidade dos dados torna-se inerente ao sistema.
Vantagens e limitações do armazenamento Irys: verificabilidade, custos e desempenho
A principal vantagem da Irys é a comprovabilidade dos dados. A rede valida continuamente a existência dos dados, eliminando a necessidade de confiança e suportando aplicações de elevada credibilidade.
A integração entre dados e execução permite às aplicações utilizar dados on-chain diretamente, reduzindo a dependência de sistemas externos — fator relevante para DeFi, IA e outros cenários semelhantes.
Contudo, o sistema é complexo, envolvendo partições, verificação e consenso, e exige recursos significativos de armazenamento e computação.
Assim, a Irys adequa-se sobretudo a ambientes que exigem credibilidade elevada dos dados, e não ao simples armazenamento de ficheiros.
Resumo
Ao unificar armazenamento, verificação e execução, a Irys estabelece uma nova infraestrutura de dados Web3. A sua inovação reside em permitir que os dados existam, sejam comprovados e participem em cálculos.
Através da partição e da verificação contínua, a Irys assegura disponibilidade dos dados a longo prazo e reduz a dependência de sistemas externos. Esta arquitetura distingue-a dos protocolos tradicionais, posicionando a Irys como referência em camadas de dados comprováveis.
Perguntas frequentes
1. Porque é que os dados da Irys precisam de verificação?
Porque as redes descentralizadas não podem depender de um único nodo; é necessário um mecanismo de verificação para garantir a existência genuína dos dados.
2. O que é uma Partition?
É a unidade fundamental de armazenamento na Irys, utilizada para guardar e comprovar uma quantidade definida de dados.
3. Para que serve o Matrix Packing?
Para associar os dados aos nodos, evitando fraudes por replicação.
4. Como é que a Irys evita a perda de dados?
O armazenamento distribuído e a realocação de partições garantem a integridade dos dados, mesmo quando nodos saem da rede.
5. Qual é a principal diferença entre a Irys e o armazenamento tradicional?
O armazenamento tradicional centra-se na preservação dos dados; a Irys foca-se em dados comprováveis que podem ser usados em cálculos.







