In real-world usage, when a developer or user submits an AI request, the system does not simply return an unverified result. Instead, the request moves through a multi-stage pipeline that includes computation, validation, and final recording. This design is driven by the need for trustworthy outputs, especially in areas like automated decision-making and data processing.
This execution flow typically spans several layers, including request entry, inference execution, result verification, and on-chain confirmation. The coordination between these components defines how OpenGradient operates.
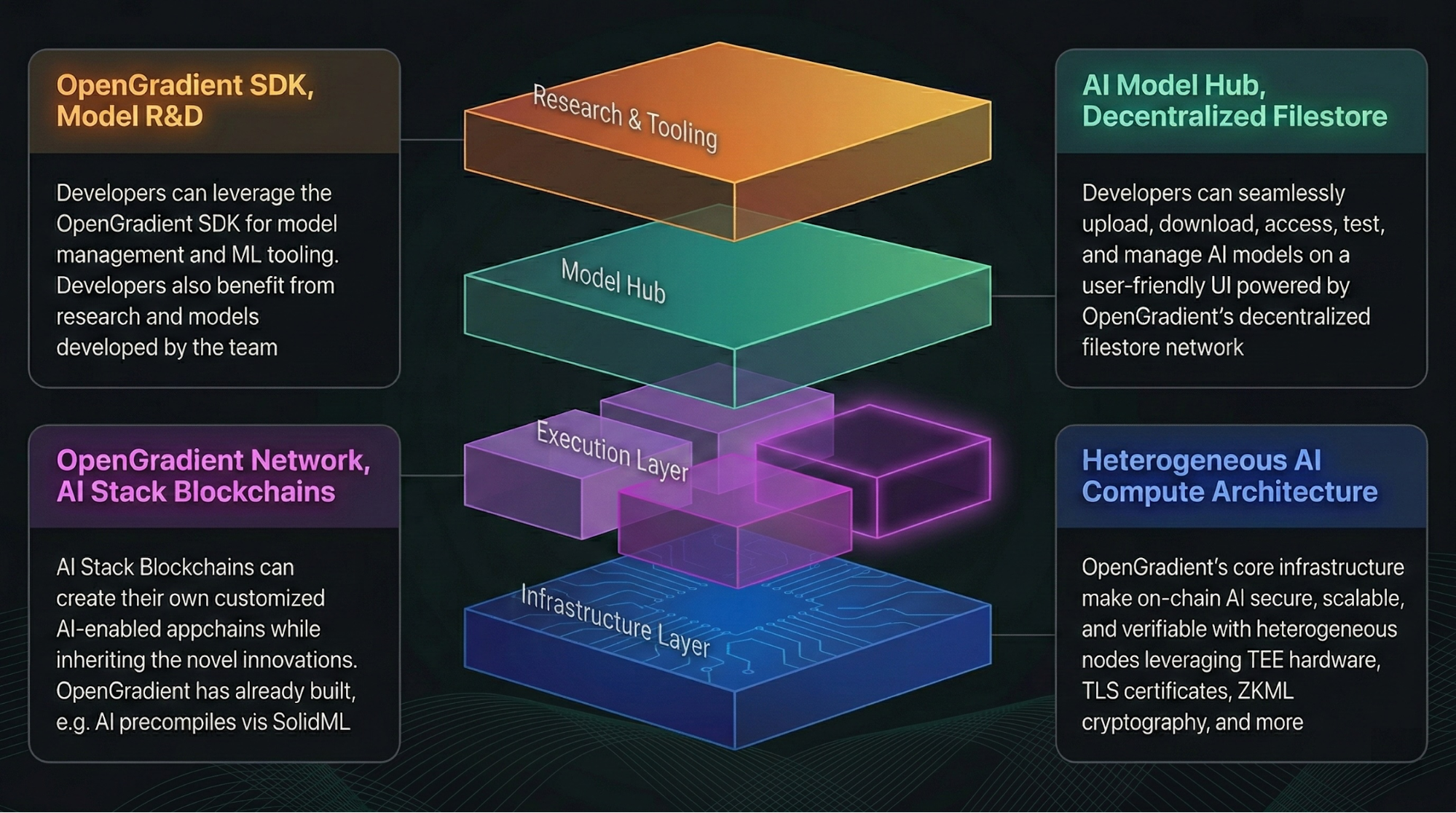
How Users Connect to the OpenGradient Network
User access is the starting point of the entire process.
At the mechanism level, developers connect their applications to the OpenGradient network via APIs or SDKs, submitting inference requests that include model parameters and input data. Once received, the system standardizes the request and prepares it for task allocation.
Structurally, the access layer sits at the outer edge of the network. It translates user requests into executable internal tasks and forwards them to the scheduling system. This layer typically includes interface services and request management modules.
The purpose of this design is to abstract away the complexity of distributed computing behind a unified interface, allowing users to interact with the network without needing to understand its internal architecture.
How AI Requests Are Submitted and Routed
The submission phase determines how tasks enter the execution pipeline.
At the mechanism level, once a request is received, the system evaluates factors such as task type, computational complexity, and node availability. It then assigns the task to appropriate inference nodes using scheduling algorithms designed to optimize resource utilization.
From a structural standpoint, the request management module logs task details and assigns a unique identifier for tracking and verification. The task is then placed into an execution queue, awaiting processing.
This approach ensures efficient allocation of computing resources while minimizing bottlenecks across nodes.
How Inference Nodes Execute Model Computation
Inference nodes handle the core computational workload.
At the mechanism level, once a node receives a task, it runs the AI model locally, processes the input data, and generates an output. At the same time, it produces accompanying proof data to support later verification.
Structurally, inference nodes include both a model execution environment and a result generation module. These typically operate within controlled environments to ensure consistency and reproducibility.
This stage is critical because it completes both the computation and the preparation for verification in a single step.
How Verification Nodes Validate Results
Verification nodes are responsible for ensuring the integrity of outputs.
At the mechanism level, they receive both the result and its associated proof data from inference nodes. Using independent computation or verification algorithms, they confirm whether the result is correct. If validation fails, the result may be rejected or recomputed.
Structurally, the verification layer operates independently from the execution layer. This separation ensures that validation does not rely on the original computing node, increasing system security.
This mechanism shifts trust from individual nodes to the broader network, making the system more resistant to tampering.
How On-Chain Recording Finalizes Results
On-chain recording provides the final layer of confirmation.
At the mechanism level, once results pass verification, they are submitted to a blockchain or data layer for permanent recording. This typically involves packaging the data and confirming it through a consensus process.
Structurally, the on-chain layer sits at the end of the pipeline. Its role is to write results into a distributed ledger, ensuring long-term traceability and immutability.
This design guarantees that results are not only verified but also persistently auditable.
How Different Modules Work Together
The coordination between modules determines overall system performance.
At the mechanism level, the access layer, execution layer, verification layer, and recording layer are connected through messaging systems and scheduling protocols. Each stage passes its output to the next in sequence.
Structurally, these components form a pipeline architecture, allowing tasks to flow continuously rather than being processed in isolation.
| Module |
Function |
Position |
| Access Layer |
Receives requests |
Entry point |
| Scheduling Layer |
Allocates tasks |
Intermediate |
| Inference Nodes |
Execute computation |
Core |
| Verification Nodes |
Validate results |
Security layer |
| On-Chain Layer |
Record outputs |
Final stage |
This coordinated structure improves throughput while ensuring that each stage has a clearly defined responsibility.
Breaking Down the Full Inference Workflow
The entire process can be understood as a sequence of steps.
At the mechanism level, a complete task typically follows this path: request submission → task allocation → model execution → result generation → verification → on-chain recording. These steps form a closed loop.
From a structural perspective, each step is handled by a distinct module, enabling clear responsibility boundaries and scalable system design.
This breakdown simplifies a complex computational process into standardized stages, improving maintainability and scalability.
Conclusion
By separating AI inference, result verification, and on-chain recording into coordinated modules, OpenGradient creates a verifiable computing pipeline. This design allows decentralized AI networks to balance efficiency with trust, making them suitable for applications where reliable results are essential.
FAQ
How does OpenGradient process AI requests?
After a user submits a request, the system assigns it to inference nodes for execution, followed by a verification process.
Why are verification nodes necessary?
They independently validate results, reducing reliance on any single node and improving trust.
What is the role of on-chain recording?
It stores final results in an immutable form, enabling auditability and long-term verification.
What is the difference between inference and verification nodes?
Inference nodes generate results, while verification nodes confirm their correctness.
Why is the process divided into stages?
A staged design improves efficiency, scalability, and security by allowing each module to focus on a specific task.







