adsrekt
用户暂无简介
adsrekt
Codex 今天工作不正常,GPT 5.4 服务器过载,我是唯一遇到这个问题的人吗?
查看原文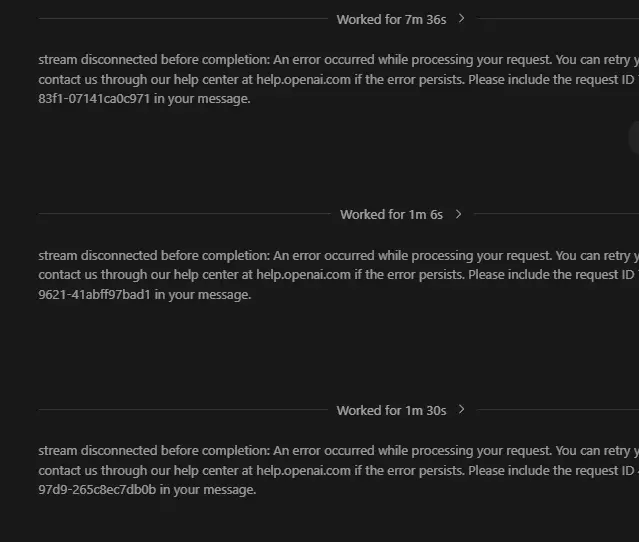
- 赞赏
- 点赞
- 评论
- 转发
- 分享
有人在苹果手表上运行了一个语音模型。不是玩具演示。Granite 4.0 1B 语音模型在OpenASR排行榜上排名第一。它的精彩之处在于:• 1B参数——只有Granite 3.3 2B模型的一半大小 • 英语转录准确率高于更大模型 • 采用推测解码,在微型硬件上实现更快推理 • 支持6种语言——英语、法语、德语、西班牙语、葡萄牙语、日语 • 关键词列表偏置,确保能正确识别名字和缩写 没有人提到的部分:你每个月都在为Whisper API调用付费,而一个比前一代模型小一半的模型却在你的手腕设备上表现优异。这不是简单的优化。这意味着边缘语音应用的整个成本结构正在崩溃。模型更小,准确率更高。完全无需云端依赖。
查看原文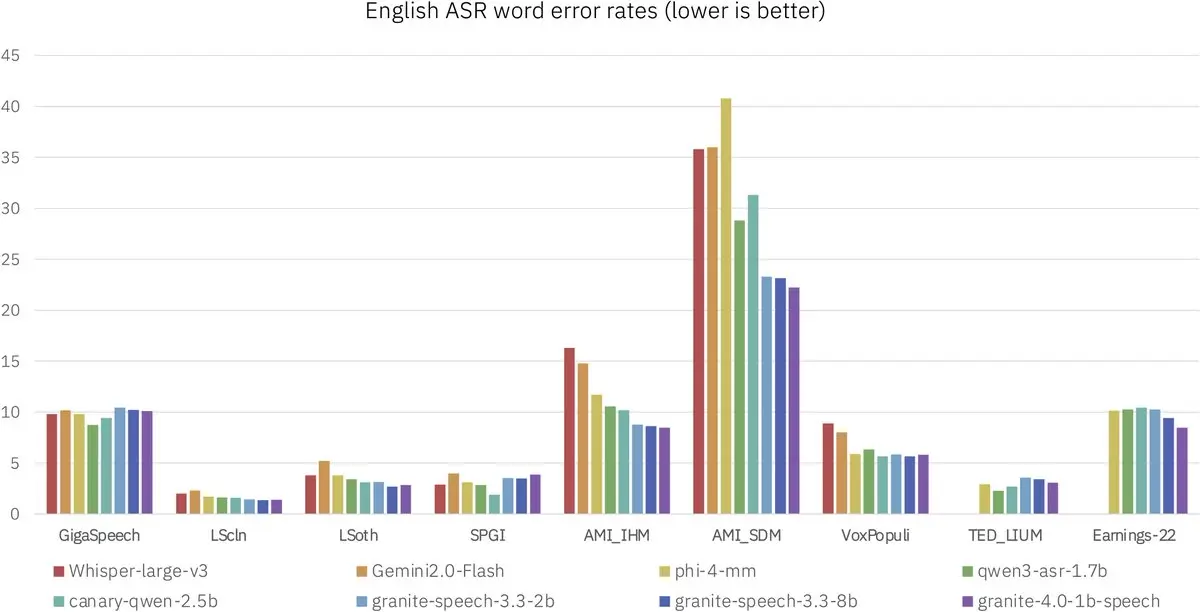
- 赞赏
- 2
- 评论
- 转发
- 分享
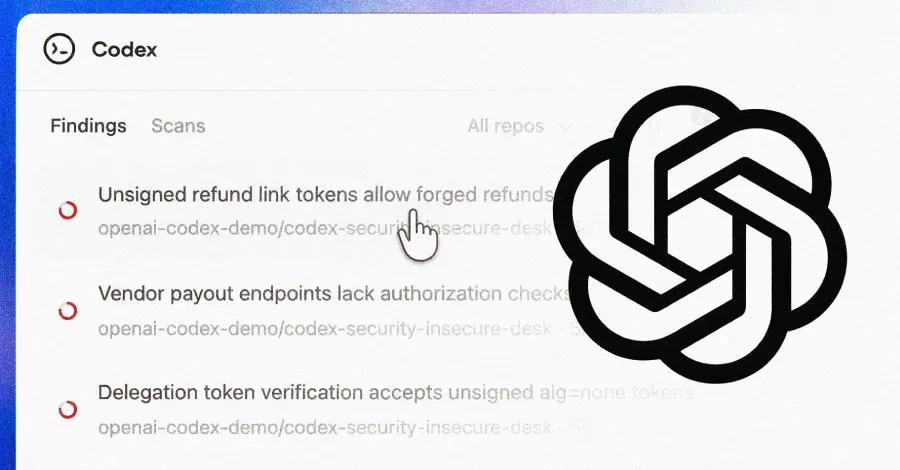
OpenAI在30天内扫描了120万次提交
他们发现了10,561个高严重性漏洞,792个关键漏洞。
在你现在可能依赖的项目中
OpenSSH、GnuTLS、Chromium、Libssh、PHP。
这些都不是业余仓库。这些是你整个技术栈所依赖的基础。而人类多年来一直错过这些问题。
Codex安全不仅仅是标记像你的linter突然崩溃的噪音。它在整个项目中构建上下文,验证发现,然后提出实际的修复方案。
这就是“你会忽略的4000个警告”和“OpenSSH中的这个特定函数让攻击者可以做一些你不想让它做的事情”之间的区别。
在ChatGPT专业版/企业版/商务版上免费试用一个月。目前处于研究预览阶段。
诚实地问一句——你真的相信你当前的CI管道能捕捉到代理刚刚在OpenSSH中发现的问题吗?
查看原文他们发现了10,561个高严重性漏洞,792个关键漏洞。
在你现在可能依赖的项目中
OpenSSH、GnuTLS、Chromium、Libssh、PHP。
这些都不是业余仓库。这些是你整个技术栈所依赖的基础。而人类多年来一直错过这些问题。
Codex安全不仅仅是标记像你的linter突然崩溃的噪音。它在整个项目中构建上下文,验证发现,然后提出实际的修复方案。
这就是“你会忽略的4000个警告”和“OpenSSH中的这个特定函数让攻击者可以做一些你不想让它做的事情”之间的区别。
在ChatGPT专业版/企业版/商务版上免费试用一个月。目前处于研究预览阶段。
诚实地问一句——你真的相信你当前的CI管道能捕捉到代理刚刚在OpenSSH中发现的问题吗?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
你交付了5个打磨过的演示版本。你没有任何用户。产品本身不是问题。
问题出在营销。
我知道,因为我在盯着一个空白的写作框数月后,建立了fcksmm,而我的项目都积灰尘。
> “如果我做得足够好,人们会找到它”
这是在公开社区中最昂贵的谎言。每天都有优秀的产品悄无声息地死去。
营销不是表演。它是分发工程。它和你的数据库、认证层一样,是技术栈的一部分。
你不会在没有错误处理的情况下交付产品,那么你为什么要在没有一篇帖子解释你做了什么的情况下交付呢?
@fcksmm_ 学习你如何从原始笔记中写作,并将它们转化为听起来像你的帖子。不是LinkedIn的风格。不是GPT的废话。是你的声音。
不是模板。不是提示链。
查看原文问题出在营销。
我知道,因为我在盯着一个空白的写作框数月后,建立了fcksmm,而我的项目都积灰尘。
> “如果我做得足够好,人们会找到它”
这是在公开社区中最昂贵的谎言。每天都有优秀的产品悄无声息地死去。
营销不是表演。它是分发工程。它和你的数据库、认证层一样,是技术栈的一部分。
你不会在没有错误处理的情况下交付产品,那么你为什么要在没有一篇帖子解释你做了什么的情况下交付呢?
@fcksmm_ 学习你如何从原始笔记中写作,并将它们转化为听起来像你的帖子。不是LinkedIn的风格。不是GPT的废话。是你的声音。
不是模板。不是提示链。

- 赞赏
- 1
- 评论
- 转发
- 分享
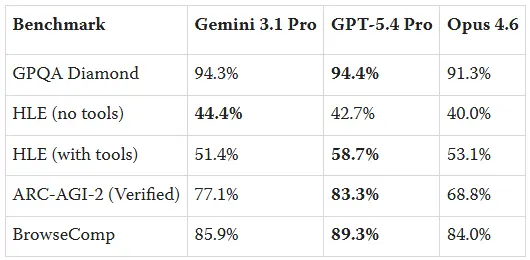
OpenAI 发布了 GPT-5.4 Pro,完全没有安全评估
没有系统卡,没有公开风险评估,什么都没有。
这可能是目前在生物研究开发、网络攻防操作和自主计算方面最好的模型——他们就像发布补丁说明一样发布了它
这也不是第一次。GPT-5.2 Pro 也遵循了同样的模式。悄悄发布,没有文档,没有外部审查。他们以前也这样做过,没有人追究责任,所以他们又这样做了
OpenAI 现在发布的前沿模型的透明度甚至比在 Huggingface 上的周末微调还要低
如果你在构建基于 5.4 Pro 的系统或在任何涉及敏感领域的管道中部署它,当模型被推动时,你完全不知道它实际上能做什么。
查看原文没有系统卡,没有公开风险评估,什么都没有。
这可能是目前在生物研究开发、网络攻防操作和自主计算方面最好的模型——他们就像发布补丁说明一样发布了它
这也不是第一次。GPT-5.2 Pro 也遵循了同样的模式。悄悄发布,没有文档,没有外部审查。他们以前也这样做过,没有人追究责任,所以他们又这样做了
OpenAI 现在发布的前沿模型的透明度甚至比在 Huggingface 上的周末微调还要低
如果你在构建基于 5.4 Pro 的系统或在任何涉及敏感领域的管道中部署它,当模型被推动时,你完全不知道它实际上能做什么。
- 赞赏
- 1
- 评论
- 转发
- 分享
GPT 5.4 提示
停止启用 1百万上下文窗口。它还没有准备好。这是用户体验的表演,正在把你的构建烧得一干二净
我在我自己的三个项目中彻底测试了新模型。不是随意检查——是真正的生产工作
这里有一些没人告诉你的事情:
抽象任务理解能力显著提升。模型终于在你逐步说明之前理解你想做什么
但那个大家都在炒作的 1百万上下文窗口?不要碰它。它还不成熟。把你的上下文放到项目文件夹和项目设置里。模型实际上就是在那里读取
启用每项技能。每个工具。把它们都最大化。当模型拥有完整权限时,它的表现就像是另一个产品,而不是默认的精简版本
还有 xHigh 模式?那是个 TOKEN 火炉。看着它在执行相同任务时摧毁了我的余额,而标准模式却能正常处理
查看原文停止启用 1百万上下文窗口。它还没有准备好。这是用户体验的表演,正在把你的构建烧得一干二净
我在我自己的三个项目中彻底测试了新模型。不是随意检查——是真正的生产工作
这里有一些没人告诉你的事情:
抽象任务理解能力显著提升。模型终于在你逐步说明之前理解你想做什么
但那个大家都在炒作的 1百万上下文窗口?不要碰它。它还不成熟。把你的上下文放到项目文件夹和项目设置里。模型实际上就是在那里读取
启用每项技能。每个工具。把它们都最大化。当模型拥有完整权限时,它的表现就像是另一个产品,而不是默认的精简版本
还有 xHigh 模式?那是个 TOKEN 火炉。看着它在执行相同任务时摧毁了我的余额,而标准模式却能正常处理

- 赞赏
- 2
- 评论
- 转发
- 分享
停止构建你的想法。从你的市场进入策略(GTM)开始。
我今年发布了三个工具。那些实现了$5k 美元月经常性收入(MRR)的工具有一个共同点——我在写第一行代码之前就知道流量来自哪里。
那些失败的工具架构更好。
你手上现在有五个打磨完毕的演示,没有用户,没有月收入(MRR),你还在调整代理循环,而不是问一个问题——我的前50个用户来自哪里。
不是你的想法,不是你的技术栈,也不是你的多代理框架。
你的创业项目的生死取决于分发渠道。
现在就做一次资源审计,看看你已经拥有的资源:你的粉丝(X粉丝)、你的Discord、你的API额度、你的细分子Reddit,以及你从那个你放弃的项目中积累的邮件列表。
那就是你的市场进入策略(GTM),那是你的起跑线。
打造适合你已经能触达渠道的产品。
查看原文我今年发布了三个工具。那些实现了$5k 美元月经常性收入(MRR)的工具有一个共同点——我在写第一行代码之前就知道流量来自哪里。
那些失败的工具架构更好。
你手上现在有五个打磨完毕的演示,没有用户,没有月收入(MRR),你还在调整代理循环,而不是问一个问题——我的前50个用户来自哪里。
不是你的想法,不是你的技术栈,也不是你的多代理框架。
你的创业项目的生死取决于分发渠道。
现在就做一次资源审计,看看你已经拥有的资源:你的粉丝(X粉丝)、你的Discord、你的API额度、你的细分子Reddit,以及你从那个你放弃的项目中积累的邮件列表。
那就是你的市场进入策略(GTM),那是你的起跑线。
打造适合你已经能触达渠道的产品。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
新的 GPT 5.4 感觉棒极了
>gpt 5.3 codex 详细描述了她的动作,但最终生成了糟糕的代码
>gpt 5.2 完全没有描述,但表现更好
>5.4 - 结合了这些优点
现在是 GPT 5.4 还是 Opus 4.6 ?
查看原文>gpt 5.3 codex 详细描述了她的动作,但最终生成了糟糕的代码
>gpt 5.2 完全没有描述,但表现更好
>5.4 - 结合了这些优点
现在是 GPT 5.4 还是 Opus 4.6 ?
- 赞赏
- 1
- 评论
- 转发
- 分享
你的AI代理现在拥有完全的root权限
只需一个幻觉命令
> sudo rm -rf /
这不是理论上的
代理循环会根据你无法控制的上下文窗口生成shell命令。模型不需要恶意。
它只需要出错一次。
查看原文只需一个幻觉命令
> sudo rm -rf /
这不是理论上的
代理循环会根据你无法控制的上下文窗口生成shell命令。模型不需要恶意。
它只需要出错一次。

- 赞赏
- 2
- 评论
- 转发
- 分享
你的手机比你的妻子更了解你。
用加密货币支付的临时号码没有历史记录,没有身份,没有束缚。
没有验证的自拍照。没有关联的银行账户。没有凌晨3点关于哪个交易所刚被传唤的焦虑。
查看原文用加密货币支付的临时号码没有历史记录,没有身份,没有束缚。
没有验证的自拍照。没有关联的银行账户。没有凌晨3点关于哪个交易所刚被传唤的焦虑。

- 赞赏
- 1
- 评论
- 转发
- 分享
“Python ‘为你管理内存’”的神话导致你的代理在运行4小时后OOM
上个月并行运行了24个多代理,消耗的tokens是单个会话的10倍,却没有任何可用输出
真正的问题并不是tokens,而是没人关注的内存
Python使用引用计数加循环垃圾回收。听起来没问题,直到你通过C扩展加载numpy数组,而这些扩展没有正确递减引用。那些对象永远不会被回收。它们就那样静静地存在,逐渐增长
每处理100个tokens的上下文,你的长时间运行的代理就会进行一次tensor分配,可能不会释放。将此乘以24个并发会话,你每天可能会泄漏400MB的内存
> 只需增加更多RAM
是的,这意味着每月花费3万美元的计算资源,来弥补tracemalloc在10分钟内就能捕获的问题
查看原文上个月并行运行了24个多代理,消耗的tokens是单个会话的10倍,却没有任何可用输出
真正的问题并不是tokens,而是没人关注的内存
Python使用引用计数加循环垃圾回收。听起来没问题,直到你通过C扩展加载numpy数组,而这些扩展没有正确递减引用。那些对象永远不会被回收。它们就那样静静地存在,逐渐增长
每处理100个tokens的上下文,你的长时间运行的代理就会进行一次tensor分配,可能不会释放。将此乘以24个并发会话,你每天可能会泄漏400MB的内存
> 只需增加更多RAM
是的,这意味着每月花费3万美元的计算资源,来弥补tracemalloc在10分钟内就能捕获的问题
- 赞赏
- 点赞
- 评论
- 转发
- 分享
你的AI是一个黑箱,这就是为什么它会耗尽你的钱包
机械可解释性是你如何打开一个大型语言模型(LLM)并映射其内部实际电路的方法
不是凭感觉测试
也不是“看起来有效”
是对模型实现逻辑的实际神经元级追踪
现在有96%的流量访问你的端点是机器人在读取原始HTML
你的模型正在做出你无法审计、无法追踪、无法解释的决策
而你却让它掌控真正资本的钥匙
企业AI安全团队都不理解自己的模型是如何工作的
他们用RLHF包裹模型并称之为对齐
那不是真正的安全,那是营销
真正的挑战在于规模——数十亿参数,而我们目前只能解释微小的电路
但这些微小电路告诉你一切
哪些神经元在价格数据上会激活
哪些神经元会完全覆盖你的RAG上下文
查看原文机械可解释性是你如何打开一个大型语言模型(LLM)并映射其内部实际电路的方法
不是凭感觉测试
也不是“看起来有效”
是对模型实现逻辑的实际神经元级追踪
现在有96%的流量访问你的端点是机器人在读取原始HTML
你的模型正在做出你无法审计、无法追踪、无法解释的决策
而你却让它掌控真正资本的钥匙
企业AI安全团队都不理解自己的模型是如何工作的
他们用RLHF包裹模型并称之为对齐
那不是真正的安全,那是营销
真正的挑战在于规模——数十亿参数,而我们目前只能解释微小的电路
但这些微小电路告诉你一切
哪些神经元在价格数据上会激活
哪些神经元会完全覆盖你的RAG上下文

- 赞赏
- 1
- 评论
- 转发
- 分享
Anthropic的收入运行速率刚刚达到$20 十亿
>$9 十亿预计在2025年底
>$14 十亿几周前
>$19 十亿现在
他们在几周内增加了$5 十亿
这不是增长,这是企业采纳的速度,除非同时签订大量API合同,否则看起来不合理。
查看原文>$9 十亿预计在2025年底
>$14 十亿几周前
>$19 十亿现在
他们在几周内增加了$5 十亿
这不是增长,这是企业采纳的速度,除非同时签订大量API合同,否则看起来不合理。

- 赞赏
- 点赞
- 评论
- 转发
- 分享
我在Codex中同时运行了24个多智能体会话
OpenAI,你在搞什么?
是单个标签页的10倍令牌
输出完全没有比专注于一个提示有任何提升
> “智能体之间协作的突现行为”
是的,突现的只是我的账单
你们付钱让智能体彼此交流,而不是产生任何东西
智能体A为智能体B总结,B再为C重格式化,C传给D,D输出的还是你本可以用一个干净的系统提示在14秒内得到的相同json
这不是架构,这是一个计算的剧场
查看原文OpenAI,你在搞什么?
是单个标签页的10倍令牌
输出完全没有比专注于一个提示有任何提升
> “智能体之间协作的突现行为”
是的,突现的只是我的账单
你们付钱让智能体彼此交流,而不是产生任何东西
智能体A为智能体B总结,B再为C重格式化,C传给D,D输出的还是你本可以用一个干净的系统提示在14秒内得到的相同json
这不是架构,这是一个计算的剧场

- 赞赏
- 1
- 评论
- 转发
- 分享
我同时在codex中开启了24个多智能体
这太糟糕了
24个智能体并行运行,消耗的tokens是单个会话的10倍,完全没有你用一个标签页和清晰提示无法实现的内容
这不是一个智能体框架。这只是一个带加载动画的token炉
OpenAI推出了一个看起来像未来的功能,如果你眯着眼睛看,但一旦你真正尝试用它构建东西,你会发现每个智能体只是反复向自己重述相同的上下文,吞噬你的预算
"iT's JuSt EaRlY" - 酷,那我为一个比昨天做得更少的测试版支付了10倍的费用
目前大科技的整个“智能体”宣传其实是用户体验的表演。漂亮的仪表盘、并行旋转器、零输出。
查看原文这太糟糕了
24个智能体并行运行,消耗的tokens是单个会话的10倍,完全没有你用一个标签页和清晰提示无法实现的内容
这不是一个智能体框架。这只是一个带加载动画的token炉
OpenAI推出了一个看起来像未来的功能,如果你眯着眼睛看,但一旦你真正尝试用它构建东西,你会发现每个智能体只是反复向自己重述相同的上下文,吞噬你的预算
"iT's JuSt EaRlY" - 酷,那我为一个比昨天做得更少的测试版支付了10倍的费用
目前大科技的整个“智能体”宣传其实是用户体验的表演。漂亮的仪表盘、并行旋转器、零输出。
- 赞赏
- 2
- 1
- 转发
- 分享
ybaser :
:
直达月球 🌕OpenClaw 无用?
我一开始不想写关于 openclaw 的任何内容,除非我自己先用过
所以我用了它。用它构建。测试了工作流程。投入了真诚的时间
这是没人要求的诚实评价
目前整个 AI 代理场景感觉就像朋友之间的群聊比赛。谁的代理听起来更酷。谁的演示更炫。谁的截图点赞更多
但当你坐下来试图用 openclaw 实际简化某些事情——替换工作流程中的某个步骤或减少手动操作——它并没有做到
它会增加步骤。它会创建新的依赖。你最终得照看你构建的东西,以节省时间
那不是工具,那是拐杖
我想找到一个让我说“好,这替代了 X,我再也不用回头”的用例。花了很多时间寻找,但还没有找到
也许会有。
所以我用了它。用它构建。测试了工作流程。投入了真诚的时间
这是没人要求的诚实评价
目前整个 AI 代理场景感觉就像朋友之间的群聊比赛。谁的代理听起来更酷。谁的演示更炫。谁的截图点赞更多
但当你坐下来试图用 openclaw 实际简化某些事情——替换工作流程中的某个步骤或减少手动操作——它并没有做到
它会增加步骤。它会创建新的依赖。你最终得照看你构建的东西,以节省时间
那不是工具,那是拐杖
我想找到一个让我说“好,这替代了 X,我再也不用回头”的用例。花了很多时间寻找,但还没有找到
也许会有。
查看原文我一开始不想写关于 openclaw 的任何内容,除非我自己先用过
所以我用了它。用它构建。测试了工作流程。投入了真诚的时间
这是没人要求的诚实评价
目前整个 AI 代理场景感觉就像朋友之间的群聊比赛。谁的代理听起来更酷。谁的演示更炫。谁的截图点赞更多
但当你坐下来试图用 openclaw 实际简化某些事情——替换工作流程中的某个步骤或减少手动操作——它并没有做到
它会增加步骤。它会创建新的依赖。你最终得照看你构建的东西,以节省时间
那不是工具,那是拐杖
我想找到一个让我说“好,这替代了 X,我再也不用回头”的用例。花了很多时间寻找,但还没有找到
也许会有。
所以我用了它。用它构建。测试了工作流程。投入了真诚的时间
这是没人要求的诚实评价
目前整个 AI 代理场景感觉就像朋友之间的群聊比赛。谁的代理听起来更酷。谁的演示更炫。谁的截图点赞更多
但当你坐下来试图用 openclaw 实际简化某些事情——替换工作流程中的某个步骤或减少手动操作——它并没有做到
它会增加步骤。它会创建新的依赖。你最终得照看你构建的东西,以节省时间
那不是工具,那是拐杖
我想找到一个让我说“好,这替代了 X,我再也不用回头”的用例。花了很多时间寻找,但还没有找到
也许会有。

- 赞赏
- 1
- 评论
- 转发
- 分享
大多数人在谈论AI代理时从未真正构建过一个
以下是目前的实际架构
工具调用代理 = 大型语言模型(LLM)大脑 + 功能注册表 + 执行循环
你将工具定义为结构化的架构。模型选择调用哪个工具并传递参数。你的运行时执行它并将结果反馈
这就是整个循环。没有魔法
像langchain或OpenAI函数调用这样的现代框架处理路由。像Vertex或Bedrock这样的云ML平台处理推理扩展,这样你就不会在空闲GPU上浪费资金
Qwen 3.5小模型——0.8B到9B参数——可以在单个节点上本地运行工具调用。与大型模型相同的基础,只是计算能力较少
边缘的关键不在于知道AI存在,而在于知道如何将工具连接到一个实际上输出结果的循环中
如果你正在构建代理,现在就放下你正在使用的框架。
查看原文以下是目前的实际架构
工具调用代理 = 大型语言模型(LLM)大脑 + 功能注册表 + 执行循环
你将工具定义为结构化的架构。模型选择调用哪个工具并传递参数。你的运行时执行它并将结果反馈
这就是整个循环。没有魔法
像langchain或OpenAI函数调用这样的现代框架处理路由。像Vertex或Bedrock这样的云ML平台处理推理扩展,这样你就不会在空闲GPU上浪费资金
Qwen 3.5小模型——0.8B到9B参数——可以在单个节点上本地运行工具调用。与大型模型相同的基础,只是计算能力较少
边缘的关键不在于知道AI存在,而在于知道如何将工具连接到一个实际上输出结果的循环中
如果你正在构建代理,现在就放下你正在使用的框架。
- 赞赏
- 点赞
- 评论
- 转发
- 分享